
DeepSeek-R1是一款专为复杂推理、编程、数学和问题解决设计的开源AI模型。它采用混合专家(MoE)架构,能动态分配资源给不同的专家子模型,在保持高性能的同时显著提升效率。本指南将介绍如何通过Ollama在GPU服务器安装DeepSeek-R1,并提供优化策略及Open WebUI网页界面配置方法。
系统要求
1、操作系统:Ubuntu 22.04或以上版本
2、内存需求:
• 小模型(1.5B-7B):至少16GB RAM
• 大模型:至少32GB RAM
3、存储空间:
• 小模型:50GB可用空间
• 大模型:最高需1TB空间
4、GPU加速(可选):支持CUDA的NVIDIA显卡
模型特性
DeepSeek-R1是基于MoE架构的语言模型,其特点和优势包括:
1、动态专家系统:仅激活任务所需的专家模块,降低延迟。
2、双版本选择:
• 完整版:保留原始性能
• 蒸馏版:通过知识蒸馏压缩模型,适合普通硬件
3、参数规模:提供1.5B至671B不同规格的模型选择
4、核心优势
• 高效性:MoE架构实现高吞吐任务处理
• 开源免费:支持商业用途和自定义开发
• 多领域能力:擅长编程/数学/逻辑推理
• 弹性扩展:从消费级硬件到企业服务器均可部署
安装步骤
安装DeepSeek所需的硬件取决于用户使用的模型类型。下表显示了每种模型所需的硬盘、显存、内存和使用场景。
| 模型名称 | 模型大小 | 硬盘要求 | 显存要求 | 内存要求 | 使用场景 |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5b | 1.1GB | ~3.5GB | ~7GB | 个人项目与轻量级任务 |
| DeepSeek-R1-Distill-Qwen-7B | 7b | 4.7GB | ~16GB | ~32GB | 小规模AI开发 |
| DeepSeek-R1-Distill-Llama-8B | 8b | 4.9GB | ~18GB | ~36GB | 中等规模编程与研究 |
| DeepSeek-R1-Distill-Qwen-14B | 14b | 9GB | ~32GB | ~64GB | 高级问题解决 |
| DeepSeek-R1-Distill-Qwen-32B | 32b | 20GB | ~74 GB | ~148GB | 企业级AI工作负载 |
| DeepSeek-R1-Distill-Llama-70B | 70b | 43GB | ~161GB | ~322GB | 大规模AI应用 |
| DeepSeek-R1 | 671b | 404GB | ~1342GB | ~2684GB | 多GPU集群与HPC AI高性能计算工作负载 |
注:
671B为唯一完整版模型,其余均为针对普通硬件优化的蒸馏版。
对于7B以上模型,建议使用企业级GPU服务器以获得最佳体验,用户可通过阿里云/腾讯云/朝暮数据等平台获取配备NVIDIA A100/V100的云服务器实例。
步骤1:安装Ollama
Ollama是一个轻量级框架,可简化本地安装和使用不同大语言模型的过程。在Linux系统上安装时,请打开终端并运行以下命令:
curl -fsSL https://ollama.com/install.sh | sh步骤2:拉取DeepSeek-R1模型
安装Ollama后,通过以下命令将DeepSeek-R1模型下载到本地:
ollama pull deepseek-r1:7B请将7B替换为实际参数大小,并确保磁盘空间充足。
步骤3:运行模型
通过以下命令在本地启动模型:
ollama run deepseek-r1:7B步骤4:性能优化
为获得最佳性能,建议采用以下优化措施:
详细日志记录:添加--verbose参数以显示响应和评估耗时。
ollama run --verbose deepseek-r1:7BGPU加速:若使用NVIDIA GPU,请添加--gpu all标志。需确保NVIDIA驱动程序已安装,CUDA环境已配置。
ollama run --gpu all deepseek-r1:32B如何为 DeepSeek-R1 安装 Web 界面
为 DeepSeek-R1 集成 Web 界面可以让你通过浏览器直观、便捷地与模型交互,包括发送消息、查看回复以及自定义对话方式。本指南将介绍如何安装并启动 Open WebUI 来运行 DeepSeek-R1。
步骤 1:安装先决条件
根据你的安装方式,需满足不同的先决条件。以下是几种可选方法:
• Docker(推荐):适合大多数用户,官方支持此方式。
• Python 3.11:适合低资源环境或手动安装。
• Kubernetes:适用于需要编排和扩展的部署场景。
本指南使用 Docker 方式安装 Web 界面。
步骤 2:运行 Open WebUI 镜像
运行 Open WebUI 镜像。如果机器上已安装 Ollama,可使用以下命令:
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main• 启用 GPU 加速:添加 --gpus=all 参数(需确保 NVIDIA 驱动已安装)。
• 仅 CPU 模式:不添加该参数,容器将以 CPU 模式运行。
检查容器是否启动:
docker ps步骤 3:访问 Open WebUI
打开浏览器,访问 http://localhost:3000 (默认端口 3000)。
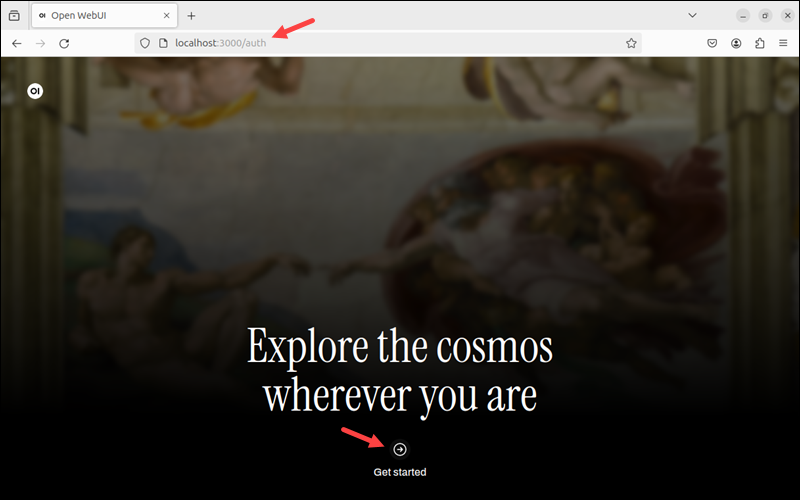
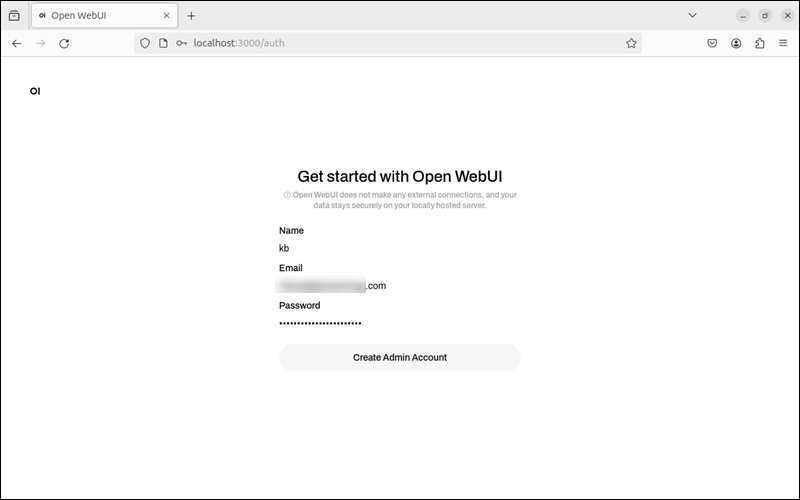
点击 Get Started 开始注册流程。填写管理员账户信息:用户名、邮箱、密码。
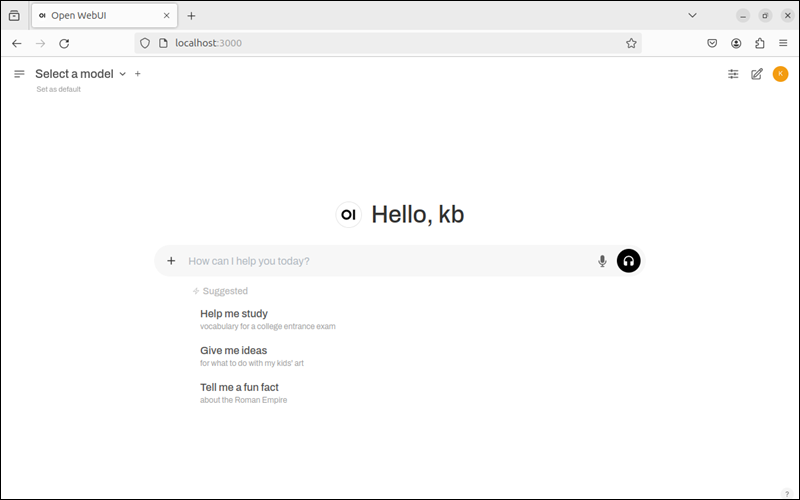
注册成功后,页面将显示聊天界面。
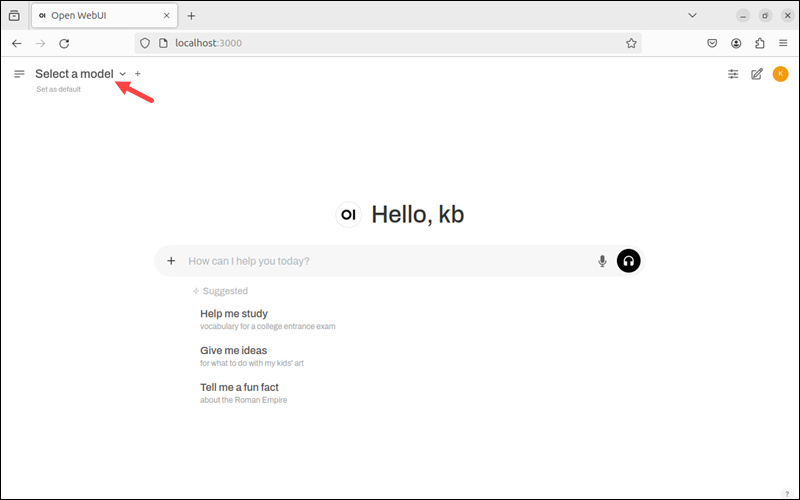
步骤 4:安装 DeepSeek-R1 模型
在导航栏中打开 Select a Model(选择模型)。
小结:本指南介绍了如何在本地安装和测试 DeepSeek-R1,并借助 Ollama 轻松部署。此外,我们还演示了如何通过 Open WebUI 搭建交互式界面,使模型更易用。